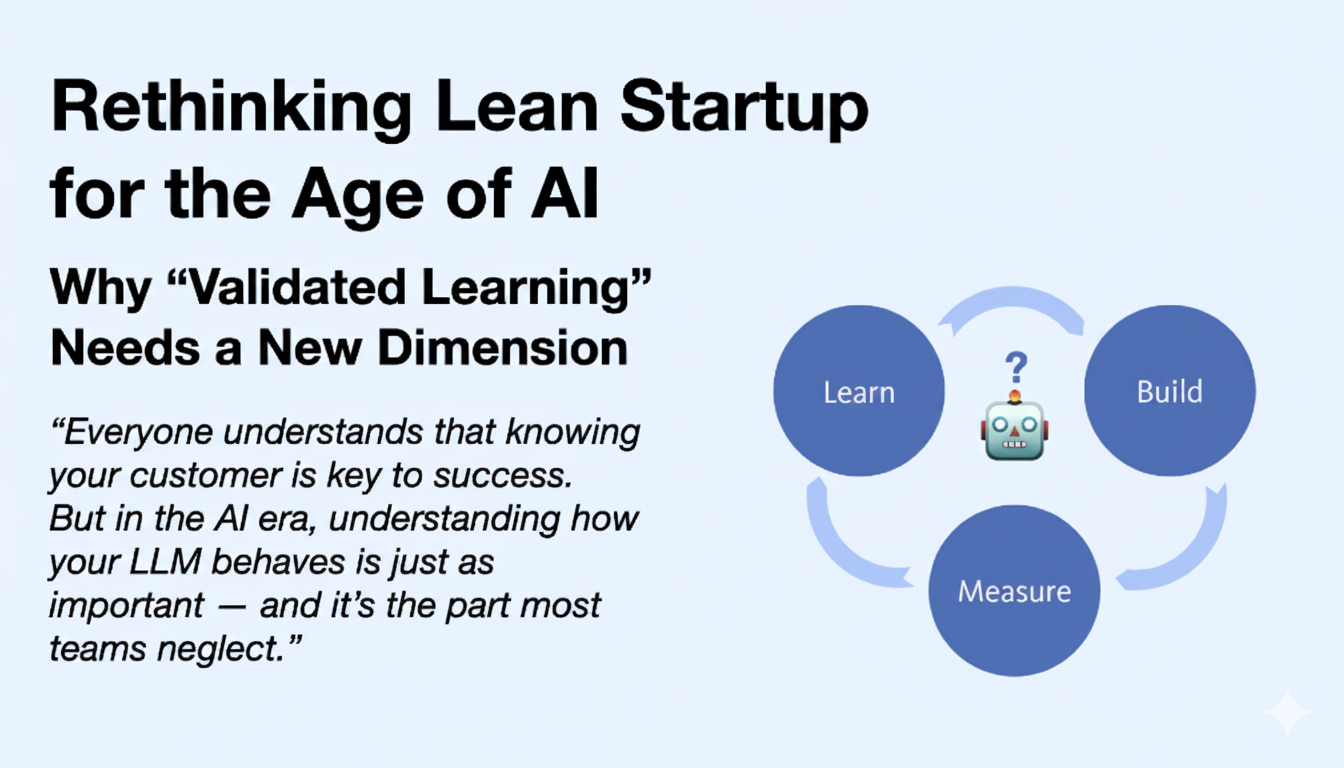
“Everyone understands that knowing your customer is key to success. But in the AI era, understanding how your LLM behaves is just as important. And it’s the part most teams neglect.”
Introduction
I’ve been revisiting The Lean Startup by Eric Ries, and while its Build → Measure → Learn loop remains timeless, generative AI introduces a new observable and improvable element to that loop: the LLM’s behavior. If your product relies on a language model, validated learning must include not only customers but also the model’s outputs.
Classic Lean Startup Loop
Lean Startup asks teams to:
- Form hypotheses about customers and value.
- Build a minimal viable product (MVP) to test them.
- Measure customer responses and behavior.
- Learn from that data, then decide whether to persevere or pivot.
Its brilliance lies in validated learning: making product decisions based on evidence, not assumptions.
The AI Twist
When LLMs power your UX, the user experience is partly generated, not only coded. That means:
- The product experience depends on model outputs, which vary by prompt, context, and model version.
- Observing only customers captures half the story.
- To validate product assumptions you must measure both customer signals and model behavior.
Ignoring the model side creates blind spots: subtle errors (hallucinations, tone drift, omitted context) can silently erode trust even while surface metrics look fine.
Error Analysis
Error analysis is the structured method for turning model outputs into measurable signals. This approach was popularized by Hamel Husain and Shreya Shankar in their course AI Evals For Engineers & PMs. It typically involves:
- Sampling representative interactions (successes, failures, edge cases).
- Defining failure modes (hallucination, omission, misinterpretation, unsafe reply, tone mismatch, etc.).
- Annotating & labeling interactions humanly or semi-automatically.
- Quantifying frequency and impact of error types.
- Prioritizing interventions (prompt changes, retrieval, fine-tuning, guardrails).
- Monitoring continuously for drift and new failure modes.
Error analysis makes the LLM a first-class object of measurement in your validated learning loop.
AI-Aware Lean Startup Loop
Here’s the same Build → Measure → Learn loop, adapted for AI products. Treat the LLM’s behavior as part of the product you measure and improve.
| Phase | Traditional Focus | AI-Aware Focus |
|---|---|---|
| Hypothesis | Customer needs, value, behavior | + Assumptions about model behavior, failure tolerance, prompt fidelity |
| Build / MVP | Minimal features and UX | + Minimal LLM integration (prompts, context selection, basic guardrails) |
| Measure | Usage, conversion, retention | + User metrics and model metrics (error counts, classified failure modes, output quality) |
| Learn | Pivot or persevere based on user uptake | + Decide also based on model reliability and error prevalence |
| Iterate | Feature/UX improvements | + Prompt tuning, retrieval augmentation, fine-tuning, hybrid rules/LLM fixes |
This extension recognizes that the AI’s responses are product outputs you must observe, quantify, and act upon.
Practical Implications
If the model is part of your product, adopt these concrete practices:
- Instrument comprehensively. Log raw inputs, full prompts, selected context, model/version/params, responses, latencies, and explicit user feedback.
- Maintain a gold set. Keep a curated, annotated benchmark of interactions to use for regression testing and continuous evaluation.
- Sample smartly. Stratify samples by user segment, query complexity, and rarity so you surface both common and edge failures.
- Automate triage. Use lightweight detectors or heuristics to pre-flag hallucinations, unsafe replies, or likely incorrect answers for human review.
- Define thresholds and alerts. Decide what error rates are acceptable for your domain and trigger alerts when exceeded.
- Close the loop. Make it fast and frictionless for product teams to convert error findings into prompt edits, retrieval rules, UI changes, or fine-tune jobs.
- Monitor drift and versions. Treat every model or prompt change as a deployment requiring regression checks.
- Respect privacy & compliance. Minimize PII in logs, implement retention policies, and control access to sensitive conversation data.
Example
Imagine a recipe suggestion app that generates personalized meal ideas based on user preferences and dietary restrictions.
- Hypothesis: users will cook more meals at home if they receive AI-generated recipe suggestions tailored to their pantry ingredients.
- MVP: a simple chat interface where users enter ingredients they have, and the LLM generates a recipe with instructions.
- Measure: track whether users save recipes, report cooking them, and return for more suggestions.
Error analysis on 200 sampled conversations reveals:
- Suggesting unavailable ingredients: 25% of recipes include ingredients the user never mentioned.
- Ignoring dietary restrictions: 15% of recipes contain allergens or restricted foods the user specified to avoid.
- Vague instructions: 18% of recipes have unclear cooking steps (e.g., “cook until done” without temperature or time).
- Unrealistic cooking times: 12% claim a recipe takes “15 minutes” when it actually requires 45+ minutes.
Interventions:
- Add explicit ingredient validation: cross-check suggested ingredients against user’s input list.
- Create a structured prompt that repeats dietary restrictions at the start of every generation.
- Use few-shot examples showing detailed, step-by-step instructions with specific times and temperatures.
- Add a post-processing check that flags suspiciously short cooking times for human review.
After implementing these changes, error rates drop significantly: unavailable ingredients from 25% → 6%, dietary violations from 15% → 2%, and user satisfaction scores improve by 40%. Users now save and cook recipes at 3x the original rate. This is clear evidence that improving model behavior directly improved the product’s value.
Why Startups Fail
Common reasons teams skip model-level validated learning:
- Demo-driven optimism. Polished demos mask real-world variability.
- Anecdotes over sampling. Teams rely on cherry-picked transcripts instead of representative samples.
- Underinvesting in instrumentation and labeling. Logging and taxonomy work is treated as optional.
- Mistaking “satisfaction” for correctness. Users may tolerate or ignore errors, producing misleading metrics.
- Updating models without regression checks. New versions can change failure profiles unpredictably.
- Treating the LLM as an oracle. If no one owns the model’s outputs as product artifacts, improvements don’t happen.
These lead to brittle products that degrade in production and frustrate customers.
Challenges & Caveats
Be realistic about the work involved:
- Labeling scale vs. cost. You can’t annotate every turn. You must sample and automate.
- Taxonomy design is domain-specific. Legal, medical, and creative apps need different failure categories.
- Causality is difficult. Failures can stem from prompts, selection of context, model quirks, or UI shaving. Isolating the root cause takes discipline.
- Drift & versioning. Continuous monitoring and regression tests are required after each model/prompt change.
- Latency vs. correctness trade-offs. Added verification steps increase response time; tune according to user tolerance.
- Privacy & compliance. Logging conversations requires careful design around anonymization, retention, and access controls.
- Organizational alignment. Error analysis must be cross-functional (product, ML, engineering, research, and ops) to translate findings into action.
Final Thoughts
The Lean Startup mantra of “validated learning wins” is more relevant than ever. But in AI products, what you validate must expand: listen to customers and measure the model’s behavior. Error analysis transforms opaque LLM outputs into actionable signals that feed the learning loop. Teams that instrument both sides and close that loop will build safer, more reliable, and more valuable AI products.
ChatIntel
Implementing robust error analysis is non-trivial, which is why we built ChatIntel. ChatIntel helps teams capture conversations, run structured error analysis, and integrate model-level signals into product decision-making. This makes it much easier to apply validated learning to both users and models.
If you’re building or scaling a conversational AI product, don’t just understand your customers. Understand your AI too. Check out ChatIntel.